本文仅作笔记使用;如何在实操中用 Textmate Grammar 自定义 VSCode 的高亮规则,参考 VSCode 的官方指南 更清楚。
VSCode 语法高亮
VSCode 能够为源文件对代码中的记号(token)依据不同语法和语义进行不同颜色的高亮显示。这是如何实现的?听说与 Textmate Grammar 有关。先不管 Textmate Grammar 是啥,进行如下观察:
在 VSCode 中打开如下的代码,
// Hash operation
unsigned int hash(HashTable *h, char *key) {
unsigned int hashval = 0;
for (; *key != '\0'; key++) hashval = *key + (hashval << 5) - hashval;
return hashval % h->size;
}在命令窗口(Ctrl+Shift+P)中选择 inspect editor tokens and scopes,把鼠标悬停在第一个 int 上面,仔细观察 “textmate scopes” 列表:
storage.type.built-in.primitive.cpp
storage.type.primitive.cpp
meta.qualified_type.cpp
meta.function.definition.cpp
source.cpp悬停到第一个 hash 上,再次仔细观察 “textmate scopes” 列表:
entity.name.function.definition.cpp
meta.head.function.definition.cpp
meta.function.definition.cpp
source.cpp注意其中重复部分。分析其它 token (记号) 的 textmate scopes,它们形成了下面这种结构(仅列出了部分记号):
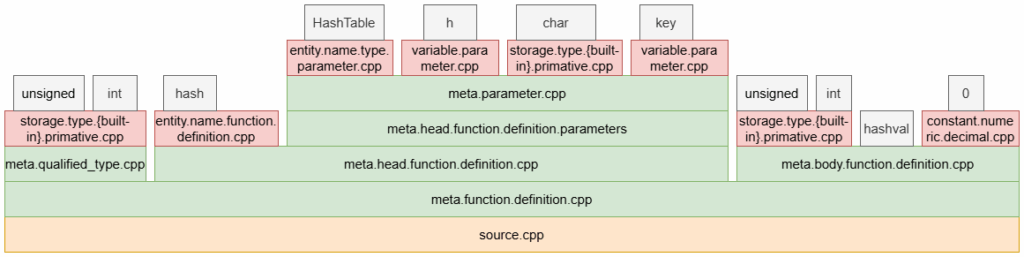
每一个 token 都像在一个栈上。事实上,这个结构和 “作用域栈” (Scope Stack) 非常像:从左向右读取 token 流,每进入一个 “作用域”,则压元素入栈;每离开一个作用域,就弹出该作用域的元素。例如,读取 HashTable 记号,进入参数列表的作用域,压 “meta.head.function.definition.parameters” 入栈;读取函数体内的第一个 unsigned,离开参数列表的作用域,弹出该元素。
这里使用的作用域被称为 Textmate Scope,它是由 Textmate Grammar 生成的。为了读懂 Textmate Grammar,有必要回顾正则表达式。
正则表达式基础备忘录
正则表达式 (regular expression) 又称模式 (pattern),可以匹配输入字符串中所有符合格式要求的字串 (可以称为 match result)。
- 一个正则表达式匹配一个输入字符串,可能匹配出来多个字串:例如只需在 VSCode 中搜索(开启正则)”int”,拥有多个 “int” 的行,每一处 “int” 都会高亮(被匹配)
- 不同的匹配结果互不重叠
- 通常以行为单位进行(有例外,具体的配置方法与提供 regex 匹配的工具有关)
对 regex 中元字符和限定符的记忆是熟练正则表达式的基础。可以一边记忆,一边利用这个 “正则表达式在线测试” 网页试验练习。或者,在 Python 中测试:
import re
>>> pat=re.compile(r"\d\.\d")
>>> pat.match("0.1")
<re.Match object; span=(0, 3), match='0.1'>
>>> pat.match("10.1")
>>> pat.search("10.1")
<re.Match object; span=(1, 4), match='0.1'>注意输入模式和被匹配字符串时的转义。
常用记号与量化限定符
上述网页给出的注解就是一个很好的备忘录。在其基础上修改如下:
常用记号
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线 (用 word 来记忆)
\s 匹配任意的空白符(用 space 来记忆,具体含义见附注1)
\d 匹配数字(用 digit 来记忆)
\b 匹配单词的开始或结束(用 boundary 来记忆,详解见附注 1)
^ 匹配行的开始,与匹配字符串整体开始的 \A 区分
$ 匹配行的末尾,与匹配字符串整体结束的 \z 区分量化限定符(quantifier)
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
注:因此 x* y+ z? 等同于 x{0,} y{1,} z{0,1}方括号表达式 (bracket expression):表示 “单个字符,多种选择” 的方法
[aeiou] 表示 {a,e,i,o,u} 中的任意一个字符
[abcx-z] 表示 {a,b,c,x,y,z} 中的任意一个字符,其中 - 表示范围,确定范围使用的大小关系是基于 ASCII 的(猜测可以扩展到 Unicode)
[-abc] 表示 {-,a,b,c} 中的任意一个字符,这里 - 被当作字面值来看待
[\t\b] 表示制表符或退格键(backspace)中的任意一个字符取反义的方法
[^x] 匹配除了x以外的任意字符
[^aeiou] 匹配除了 {a,e,i,o,u} 以外的任意字符。可以理解为 [^ ] 比字符串接结合优先级更低
[^-abcx-z] 匹配除了 {-,a,b,c,x,y,z} 以外的任意字符
\W, \S, \D, \B 分别匹配任意不属于 \w, \s, \d, \b 的字符量化限定符的贪婪匹配与懒惰匹配
对于量化限定符,regex 默认试图匹配尽可能多的字符,称为 “贪婪匹配” (greedy matching)。这个 “尽可能多” 是在整个 pattern 仍然能匹配字符串的情况下:
对于正则表达式 a[bc]+bc
它匹配 acbcb,匹配结果是 acbc(不会因为试图匹配尽可能多的 b 或 c 而让整体失配)
它匹配 acbcbc,匹配结果是 acbcbc我们可以更改这种行为,让它匹配尽可能少的字符,只需在量化限定符后面加一个 ? 即可。这被称为懒惰匹配(lazy matching):
对于正则表达式 a[bc]+?bc
匹配 acbcbc,匹配结果是 acbc组合方法
用括号可以调整操作符的优先度:gr(a|e)y 等价于 gray|grey
用括号可以捕获,用 \1,\2,… ,\9 可以引用先前捕获的内容(注意 9 个捕获组的限制):
gr(e|a)y=\1 能够匹配 grey=e 以及 gray=a使用 (?:pattern) 仅仅利用括号调整优先级,而避免捕获的副效果:
gr(?:e|a)y(\d+)=\1 能匹配 gray12=12,不匹配 grey12=e正则表达式实战:Textmate Grammar
在代码编辑器中匹配程序源文件,这是正则表达式的经典使用场景之一。MacOS 上的 TextMate 文本编辑器允许用户自定义正则表达式嵌套地匹配文本内容,从而并匹配到的内容进行语法高亮。由于并非真的需要使用 TextMate 编辑器,只是为了理解沿用 TextMate Grammar 的惯例,所以在这里只举几例感受一下。
截取控制关键词
从 Textmate Language Grammar 网页截取示例语法,分析其中正则表达式匹配的内容:
1 { scopeName = 'source.untitled';
2 fileTypes = ( );
3 foldingStartMarker = '\{\s*$';
4 foldingStopMarker = '^\s*\}';
5 patterns = (
6 { name = 'keyword.control.untitled';
7 match = '\b(if|while|for|return)\b';
8 },
9 { name = 'string.quoted.double.untitled';
10 begin = '"';
11 end = '"';
12 patterns = (
13 { name = 'constant.character.escape.untitled';
14 match = '\\.';
15 }
16 );
17 },
18 );
19 }其中
- foldingStartMarker 匹配以右花括号结束的行,其中
\s*负责匹配右花括号到行尾之间任意多个空白字符。 - foldingEndMarker 匹配以左花括号开启的行,其中
\s*匹配行开头到左花括号之间任意多个空白字符。 - keyword.control.untitled 匹配独立出现的 if, while, for, return 关键词。其中
\b负责匹配符号边界。 - string.quoted.double.untitled 匹配双引号标志出的字符串。constant.character.escape.untitled 匹配字符串中的转义字符。所谓转义字符,就是单个反斜杠(1)加上另一个字符(2)组成的两字符序列。体现在正则表达式中,
\\匹配单个反斜杠(1),.匹配任意一个字符(2)。 - 匹配/搜索转义字符的范围是双引号字符串内部,这是一种嵌套匹配机制。因此匹配到的转义字符会被标记为
string.quoted.double.untitled, constant.character.escape.untitled
这里使用 \b 而不是空格,可以识别出控制关键词和其它记号来在一起的情况。例如, \bfor\b 对下面若干行的匹配情况如下:
for(int i=0 # match
for (int i=0 # match
forge # no match截取 here-doc
here-doc 是一些语言定义多行字符串的方式。如在 Shell 语言中:
cat <<EOF
This is a multi-line string.
It can contain any text, including special characters like "quotes".
EOFEOF 就是分界记号。
如下的规则可以截取 here-doc,注意 end 中的 \1 是正则表达式中的截获引用机制,匹配 begin 中截获的组。截获引用为什么从 1 开始计数?因为 \0 已经有代表 NULL 字符的含义。
{ name = 'string.unquoted.here-doc';
begin = '<<(\w+)'; // match here-doc token
end = '^\1$'; // match end of here-doc
}高亮颜色选择:Scope Selector
了解了 Textmate Grammar,有了文法,就有解析树 / 作用域栈。我们至此了解了最初绘制的 Scope Stack 是如何得到的。那么,每个记号有了一列由浅入深的 textmate scopes(即作用域栈),如何为它选择高亮颜色呢?Textmate 使用 Scope Selector 作用域选择器,每个域选择器指定一种高亮颜色应用于匹配的部分即可。
域选择器是一个由空格分隔的有序列表,如 source.php string。它若要要匹配作用域栈,列表中的全部要求必须按顺序得到匹配(前缀匹配即可),比如
source.php string 这一域选择器可以匹配如下作用域栈:
text.html.basic
source.php.embedded.html
string.quoted.double.php
匹配部分已加粗当多个作用域栈都与当前作用域栈匹配时,按如下规则决出胜负(直接翻译 13.5 小节):
- 匹配到作用域栈中更深的作用域,胜出。例如,面对作用域
source.php string.quoted,域选择器string比source.php更优。 - 深度相同时,匹配最长者胜出。例如,面对作用域
source.php string.quoted,域选择器string.quoted比string更优。 - 各个 Scope Selector 抵达的最深作用域深度相同且匹配长度相同时,将这个最深的作用域删除,重新从 1 开始应用规则
Textmate 的 Scope Selector 和 Hierarchical CSS Selector 有点相似又有诸多不同,在这里就不详细叙述了。
实际创建一个 VSCode Syntax Highlighting 插件
初识 VSCode 插件及概览
如果是第一次接触 VSCode 插件开发,可以跟着这个 Hello World 教程 开发一个示例插件,先确保环境已经配好。熟悉构建、运行和调试(用 Extension Generator 创建模板工程后,进入插件开发 Workspace;在开发 Workspace 中按下 F5,构建运行插件,从而获得一个目标插件的 Demo Workspace)的流程,获得一个全局的认识。
Syntax Highlighting 插件只负责定义语言的 Textmate Grammar,从而给解析源文件获得 token 及对应的 Scope Stack。这是一个插件(New Language Support > Syntax Highlighting 类别)。用 Scope Selector 选择高亮颜色是另一个插件,即 Color Theme 类别 插件的功劳。两者可以自由组合,如你可以之定义一个新语言的Textmate 文法,然后用 VSCode 已有默认的 Color Theme 选择颜色。
具体流程
具体流程按照教程的步骤走就可以了。插件最主要的部分在 abc.tmLanguage.json 中,在其中定义文法。这个文件应该已经填充了模板内容,因此直接构建运行即可。在 Demo Workspace 中,创建 hello.abc 文件并在其中书写内容,在命令窗口中选择 inspect editor tokens and scopes,即可看到 abc.tmLanguage.json 中的文法解析源代码并为 token 分配 Scope Stack。
附注
附注1:常用正则记号详解
\b 比较特殊,它匹配 “长度为 0” 的字符,也就是数字字母 (alphanumeric, 相当于 \w) 字符与非数字字母字符 (相当于 \W) 的边界。可以理解为(^\w|\w$|\W\w|\w\W)。这个回答提供了具体的用例。
注意 \b 在方括号表达式内就不会被用来匹配边界,而是表示作为单个字符的退格键。转义问题是一个更深的兔子洞,在此按下不表。
\s 空白字符(whitespace character)包括空格、换行、tab 等字符。具体而言,等价于 [ \t\r\n\v\f],共六个字符,分别是:Space 空格 Tab 制表符 Return 回车 Newline 换行 Vertical Tab 竖直制表符 Form Feed 换页符
Leave a Reply